ДИСКЛЕЙМЕР: Я не программист и не линуксоид, а лишь энтузиаст-копипастер, который делится тем, в чем смог разобраться. Поэтому, не исключено, что знающие специалисты некоторые моменты или формулировки могут счесть неправильными или нелепыми. Подача данного материала предполагает, что вы обладаете базовым уровнем знаний Liquidsoap. Данный пример актуален для Ubuntu 22.04 и версии Liquidsoap 2.2.0, в 2.1.4 - код не работает! Как бы то ни было, следующие статьи и туториалы помогут вам разобраться: Создание 24/7 радио-стрима (Liquidsoap) Создание 24/7 радио-стрима ч.2 (Liquidsoap) Кулстори: как устроены последние апдейты на Mikulski_Radio
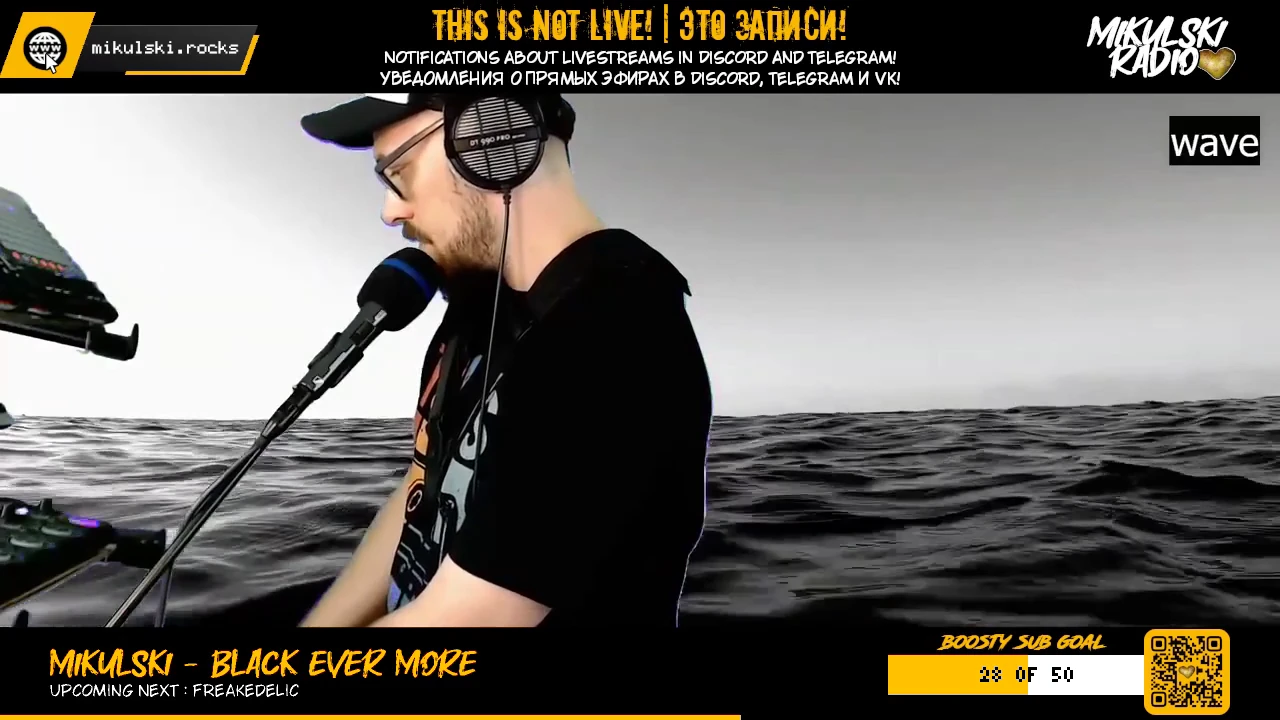
Что ж, продолжаю «закрывать гештальты»: реализовывать идеи, которые приходили еще на заре становления Mikulski_Radio. Совсем недавно получилось сделать переключение источников с плейлиста на удаленный стрим из OBS, а теперь вот удалось сделать виджет цели. Пускай не такой нарядный, но зато рабочий.
Как я упоминал в одной из первых статей на тему Liquidsoap, то в нем не предусмотрена возможность отрисовывать OBS-виджеты, так как нет встроенного браузера. А потому все ставшими привычными алерты и полоски сборов невозможно добавить в трансляцию.
Однако, после того как стало понятным, на примере прогресса воспроизведения, что можно в реальном времени отрисовывать простые прямоугольники, то я сразу пришел к мысли, что можно будет нарисовать собственный виджет. Однако, оставалось непонятным как автоматизировать процесс получения данных, чтобы не вбивать их в параметры вручную. Особенно, в тех случаях, когда нет официального API у сервиса, с которого необходимо получить нужную информацию.
Веб-парсинг
Чтобы вы понимали насколько я ничего не понимаю в программировании: то я до недавнего времени думал, что если у операционной системы нет графической оболочки, то все прелести использования обычного веб-браузера закрыты. Конечно, было очевидным, что какое-то общение с веб-ресурсом можно настроить в виде обмена запросов. Но, представьте мое удивление, когда у меня всего за несколько редакций скрипта получилось удаленно сделать скриншот страницы, а потом еще и войти в аккаунт, введя логин и пароль!
Вот тогда я и подумал, что раз уж у Boosty нет публичного API, то можно брать актуальное количество подписчиков прямо со своей страницы.
В примере со скриншотом это была библиотека puppeteer для nodejs. Но так как она достаточно прожорлива по ресурсам, то пришлось поискать другие более легковесные варианты. После перебора нескольких репозиториев, я остановился на связке unirest + cheerio:
npm i unirest
npm i cheerioconst unirest = require("unirest");
const cheerio = require("cheerio");
const getData = async() => {
try{
const response = await unirest.get("<адрес страницы с которой будет парсинг>")
const $ = cheerio.load(response.body);
const selector = $('<сюда вставляется селектор>').text();
console.log(selector);
}
catch(e)
{
console.log(e);
}
}
getData(); Чтобы забрать информацию из конкретной области страницы, то нужно скопировать его, так называемый css-selector: правый щелчок мыши в интересующем месте -> исследовать -> скопировать -> скопировать селектор.
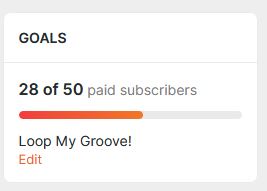
Вот отсюда я решил забирать число подписчиков.
Так как данные тут поступают в виде «28 из», то пришлось отсечь ненужные символы с помощью slice().
Вот что в итоге получилось уже с записью числа в файл:
const unirest = require("unirest");
const cheerio = require("cheerio");
const getData = async() => {
try{
const response = await unirest.get("https://boosty.to/mikulski")
const $ = cheerio.load(response.body);
const boosty_count = $('span.TargetItemCommon_collectedTextTarget_McKGZ:nth-child(1)').text();
const boosty_subs = boosty_count.slice(0, 2);
console.log("Current count of Boosty subs: " + boosty_subs);
fs.writeFile(boosters_file, boosty_subs, (err) => {
if (err) {
console.log(err);
}
}
)}
catch(e)
{
console.log(e);
}
}
getData(); Оставалось только обернуть это все в функцию и настроить интервал выполнения. Но тут я понял, что из-за регулярных запросов — ip моего сервера может запросто угодить в бан. Почитав некоторые рекомендации по парсингу, я узнал, что следует добавлять в парсер сбор Cookie, а также информацию User-Agent — то, как представляется мой виртуальный браузер для конечных ресурсов и прочие нюансы, которые все равно в конечном итоге не гарантируют избежания бана.
Но чуть погодя я понял, что могу привязать исполнение сбора количества подписчиков через мой любимый watchFile: ведь уже есть телеграм-бот, который подключается к веб-сокету DonationAlerts и постит оповещения о поступающих донатах — https://mikulski.rocks/ru/alerti-v-telegram-donationalerts/
Так как к аккаунту DonationAlerts прилинкован мой Boosty, то подписки на нем так же воспринимаются ботом как будто это поступивший донат (честно говоря, я просто не знаю как разделить эти события, поэтому все приходит в общей массе). В общем, как бы то ни было, теперь есть событие к которому можно прицепиться, а следовательно минимизировать количество запросов к сайту.
Ну, а дальше по сложившейся привычной практике: определил файл (count_trigger), за которым будет следить парсер и в который будет вносить изменения телеграм-бот, когда будет приходить событие о донате.
Для дальнейшего вывода текста в виджет, назначил файл boosty_count_txt, чтобы число подписчиков также менялось и на экране стрима (в виде, «<n> из 50»).
Заодно, на всякий случай, добавил сбор куки и референс User_Agent (хотя не уверен, что сделал все правильно):
const boosters_file = './boosty_count';
fs.watchFile("./count_trigger", (curr, prev) => {
const getData = async() => {
try{
const response = await unirest.get("https://boosty.to/mikulski")
.jar(CookieJar)
.header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36');
const $ = cheerio.load(response.body);
const boosty_count = $('span.TargetItemCommon_collectedTextTarget_McKGZ:nth-child(1)').text();
const boosty_subs = boosty_count.slice(0, 2);
console.log("Current count of Boosty subs: " + boosty_subs);
fs.writeFile(boosters_file, boosty_subs, (err) => {
if (err) {
console.log(err);
}
fs.writeFile(boosty_count_txt, `${boosty_subs} of 50`, (err) => {
if (err) {
console.log(err);
}
});
});
}
catch(e)
{
console.log(e);
}
}
getData();
});Виджет
Настало время заняться непосредственно рисованием виджета. Сначала нарисовал подложку, поверх которой уже будет «ползти» прямоугольник прогресса. Цвет, расположение, высота и ширина.
s = mksafe(playlist("путь/к/видеофайлам"))
s = video.add_rectangle(color=0xffffff, x=50, y=315, height=30, width=280, s)Далее добавил чтение файла (file.contents), в который сохраняется число подписчиков, конвертацию из string (именно такие данные выходят при чтении файла) в int (целое число) и добавил статичное число/цель (50), чтобы отрисовка была в процентном соотношении. Конвертация нужна для того, чтобы «рисовальщик» корректно мог распознать данные параметра width для прямоугольника. Иначе Liquidsoap выдаст ошибку и не запустится.
boosty_count = string.to_int(file.contents("./boosty_count"))
s = video.add_rectangle(color=0xffffff, x=50, y=315, height=30, width=280, s)
s = video.add_rectangle(color=0xfcb900, x=50, y=315, height=30, width=(280*count / 50), s)Проблема в том, что оператор file.contents прочитывает файл единожды на старте Liquidsoap и все. На изменения файла он уже не реагирует. Оператор file.getter, который читает файл регулярно, отдает данные уже не в виде string, а в виде {string} и при конвертации в string.to_int, получается {int}. Тоже самое происходит, если написать функцию, в которую вложен file.contents. Рисовальщик, разумеется отказывается принимать это в таком виде.
В общем, достаточно много времени я потратил на то, чтобы перепробовать различные подходы и методы конвертации. Пока не обратил внимание на оператор ref — «создает ссылку, т.е. значение, которое может быть изменено». И после бессчетного количества попыток, я наконец смог написать функцию. Смысл был в том, чтобы вычисления для width вынести в отдельную переменную, а не пытаться все рассчитать внутри video.add_rectangle:
n = ref(0)
def count_func()
n := (256*(string.to_int(file.contents("./boosty_count"))) / 50)
endЕсть нюанс: чтобы определить тип данных для ref, нужно обязательно в скобки вписать в качестве аргумента изначальное значение. И после этого ref сам поймет, что от него требуется хранить в себе: число, число с точкой или строку. В этом есть и свое неудобство: при запуске Liquidsoap — виджет будет сбрасываться к этому первоначальному значению, пока не произойдет вызова функции с чтением файла.
n = ref(143)
def count_func()
n := (256*(string.to_int(file.contents("./boosty_count"))) / 50)
endФункция будет запускаться через file.watch, то есть будет срабатывать на изменения все в том же файле boosty_count. Вот как это все выглядит в целом, с уже наложенным текстом (<n> из 50):
s = mksafe(playlist("путь/к/видеофайлам"))
n = ref(143)
def count_func()
n := (256*(string.to_int(file.contents("./boosty_count"))) / 50)
end
file.watch("./boosty_count", count_func)
#widget
s = video.add_rectangle(color=0xffffff, x=888, y=655, height=40, width=256, s)
s = video.add_rectangle(color=0xfcb900, x=888, y=655, height=40, width=n, s)
#inner_text
boosty_count_txt = file.getter("./boosty_count_txt")
s = video.add_text(color=0x000000, x=980, y=667, size=15, boosty_count_txt, s)Затем немного шаманства с оверлеем и примеркой и вот что получилось в итоге: